FaceFX Support
FaceFX Documentation and support
Additional Language Framework
FaceFX provides a framework to add new languages or custom word pronunciations to the stock FaceFX Analysis.
Table of Contents
System Architecture
The ultimate goal of the language module is to supply phonetic pronunciations to FxAnalysis. It does this in two main stages.
Tokenization
The first task of the language module is to break an input text stream into “words”. Each of these words will be input to the pronunciation generation step.
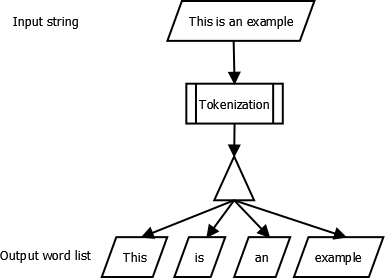
Customization
The default tokenizer breaks the string into words based on the locale setting in the dictionary file for the language. It is recommended that this be set correctly even if no dictionary words are supplied just so tokenization is correct. If, however, you want to supply your own custom tokenizer, that will take precedence. See below for the tokenizer flow:
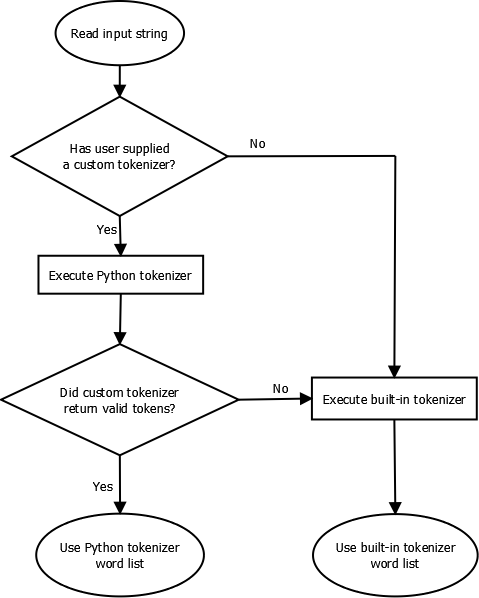
A custom Python tokenizer is a function that takes a Unicode string and returns a list of Unicode strings. For example:
1: def custom_tokenize(input_string):
2: return input_string.split
That custom tokenizer simply splits the string on spaces:
1: In [1]: def custom_tokenize(input_string):
2: ...: return input_string.split(u' ')
3: ...:
4: In [2]: custom_tokenize(u'this is an example')
5: Out[2]: [u'this', u'is', u'an', u'example']
To register the custom Python tokenizer, call the following function:
1: import FxAnalysis
2: FxAnalysis.registerLanguageTokenizer('MyLanguageName', custom_tokenize)
At this point, “MyCustomLanguage” will appear as a language in the New Animation wizard.
 The first parameter to all Python analysis language callback registration functions is the language name. The language name must exactly match for all callbacks for a language, and it must exactly match the filename of the custom dictionary in the AnalysisLanguages folder. For more information, type
The first parameter to all Python analysis language callback registration functions is the language name. The language name must exactly match for all callbacks for a language, and it must exactly match the filename of the custom dictionary in the AnalysisLanguages folder. For more information, type help(FxAnalysis) in FaceFX Studio’s python shell.
Pronunciation
The second task of the language module is to generate pronunciations for each word produced by the tokenizer. These custom pronunciations will be supplied to the analysis engine where they will be aligned to the audio. There are two phases. First, the module tries to look up the word in the language’s custom dictionary. If that fails, the module tries to execute rule-based pronunciation generation code, either in built-in to FaceFX Studio or user-defined from Python.
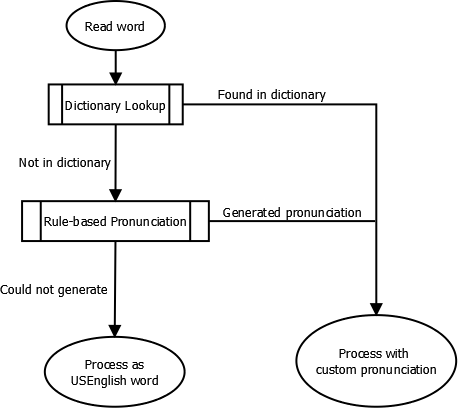
Dictionary Lookup
The dictionary lookup step is entirely self-contained in FaceFX Studio. To supply pronunciations to this step, see the Dictionary File Format section below.
Rule-based Pronunciation
See below for the flow of the Rule-based Pronunciation:
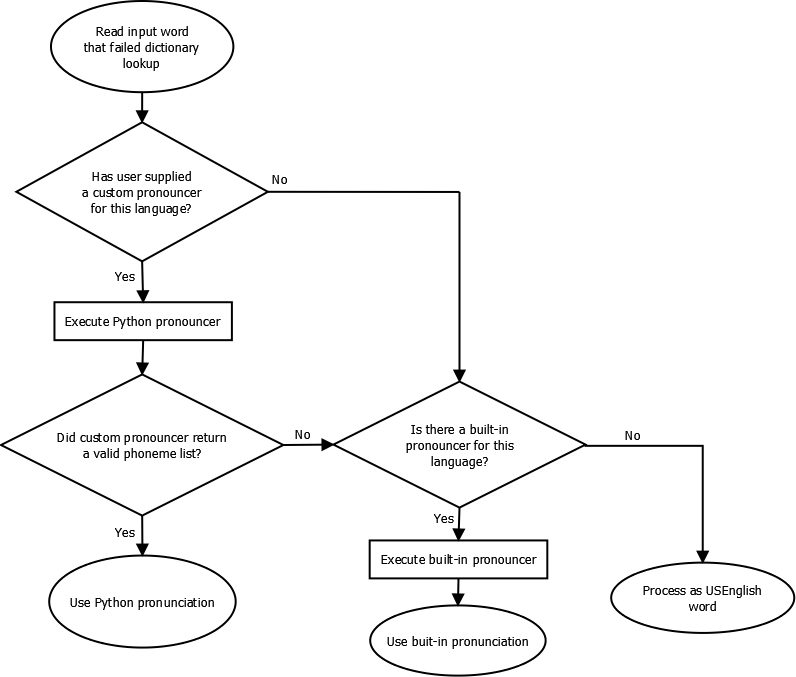
In general, there will not be a built-in pronouncer for a non-default language. Therefore, you’ll need to register a Python callback to implement the rules for your custom language. A pronouncer is a Python function that takes three Unicode strings representing the previous, current, and next words as input, and returns a list of possible pronunciations. A possible pronunciation is a list of phonemes. A phoneme is a Unicode string in the specified phonetic alphabet.
 The valid phonetic alphabets are facefx, sampa, and ipa. For a list of the phonemes in these alphabets, please see the FaceFX Phoneme List.
The valid phonetic alphabets are facefx, sampa, and ipa. For a list of the phonemes in these alphabets, please see the FaceFX Phoneme List.
A valid, but useless, custom pronouncer would be one that always returns “Hello”. Let’s create that.
1: def say_hello(prev_word, curr_word, next_word):
2: # Note that you aren't required to return alternate
3: # pronunciations. Here, I just return one. To return
4: # alternates, use the form: [[pron1], [pron2], [pron3]]
5: return [u'H', u'EH', u'L', u'O']
The custom pronouncer takes as input three strings. The prior word, the current word, and the next word. This is to take into account those languages whose words change pronunciation based on surrounding words. To analyze a file with this custom pronouncer, we need to register it:
FxAnalysis.registerLanguagePronouncer('MyCustomLanguage', 'facefx', say_hello)
Note that when registering the pronouncer, you must tell FaceFX what phonetic alphabet you will be returning pronunciations in. Here, I’ve used FaceFX’s internal alphabet because it’s all ASCII and easy to type.
 If you are using IPA, make sure your pronouncer script is encoded in UTF-8, and place this cookie at the top of the file so Python handles it correctly:
If you are using IPA, make sure your pronouncer script is encoded in UTF-8, and place this cookie at the top of the file so Python handles it correctly: # -*- coding: utf-8 -*-
At this point, MyCustomLanguage will split all input strings on spaces and try to say “hello” for every word in the text stream. It’s not exactly useful, but it’s a great base to build your own custom languages from.
Finally, it’s worth noting that any .py file in the Analysis Languages* subdirectory is assumed to be a rule-based pronunciation definition, and is automatically executed. See Czech.py in that directory for how to handle this.
Dictionary File Format
To create custom dictionaries, place an appropriately-named file in the \Analysis Languages\ subdirectory of your Documents\FaceFX Studio 20xx folder. It should be named LanguageName.dict. Every file in that folder matching *.dict will be automatically loaded by FaceFX Studio on startup.
You can use dictionaries to add support for new languages to FaceFX (like we did with ChineseMandarin.dict ) or you can create a dictionary to override the pronunciation of a few words to an already supported language. For example, you could specify pronunciation for a handful of words from the Lord of the Rings universe with the following custom pronunciation dictionary:
# Dictionary to add some custom Tolkien words to USEnglish.
# Version 1 FaceFX pronunciation dictionary
FaceFXPronDictVer=1
# Uses FACEFX phonetic alphabet. ("SAMPA" and "IPA" also valid)
FaceFXPronDictAlphabet=FACEFX
# Tokenize according to US English rules.
FaceFXProcessingLocale=en_US
# Dictionary word characters should be included. Try to filter everything else.
FaceFXLanguageTextFilterPattern=[^\u0020-\u206F] > ' ';
mordor=M O RA D O RA
uruk=UW R UW K
hai=HH AA IY
isengard=AY S EH N G AA R D
sarumon=S AA R UW M AA N
sarumon's=S AA R UW M AA N S
Notice we set the processing locale to en_US. This changes how the language will be tokenized. We recommend setting this field to the language you will be implementing. See Czech.dict for more details. The format of this field is [iso language code]_[ISO COUNTRY CODE].
If that dictionary was saved as Tolkien.dict in the Analysis Languages subdirectory, you could choose to analyze phrases for a LotR-based game with the “Tolkien” language. The words defined in the dictionary would use the custom pronunciation, and everything else would fall back on USEnglish. Alternatively, the dictionary could be saved as USEnglish.dict and you would accomplish the same thing, but by overriding the USEnglish pronunciation directly.
Adding a custom dictionary to UKEnglish, French, Spanish, German, Italian, Korean, and Japanese is difficult because you can only use phonemes that exist in that language’s neural net (the phonemes that are returned by the default analysis results). Creating an override dictionary for USEnglish (or any custom language because they fall back to USEnglish) is slightly easier as all phonemes are translated into the USEnglish equivalents, but see below for more information about diphthongs.
Use of Diphthongs in Custom Dictionaries
In FaceFX 2018 and prior versions, a bug prevented the use of diphthongs in USEnglish (and custom language) dictionaries. The bug also impacted the French and German phonemes EN, AAN, AON, OEN. In 2018.1 and beyond, this issue has been fixed, but keep in mind that diphthongs may be converted into their component vowlels as part of FaceFX coarticulation.
Text Filtering Override
In the example dictionary above, the FaceFXLanguageTextFilterPattern is set and everything outside of the 0020-206F character range is converted to a space. This is consistent with the default behavior, so the line in this example has no effect other than to demonstrates how to override the default text filter pattern for a language.
In general, you should not need to override a text filter pattern, but it can be useful in the following cases:
- When words in the dictionary you are implementing are outside of the default character range (see ChineseMandarin.dict )
- When a specific character or range of characters is causing instability in the application.
The default text filtering ranges are specified below:
- Default range - 0020-206F
- Japanese - Default range + 3040-31FF
- Korean - Default range + AC00-D7AF